来自 Hey~YaHei! 的投稿,感谢~
一直以来,树莓派以其良好的社区生态,广受嵌入式爱好者、创客欢迎。在一些相关的社区上(比如树莓派实验室),我们可以看到非常丰富的应用示例及其教程。但在树莓派上的深度学习应用并不常见,这主要是受到树莓派计算力的限制,比如之前看到过有人把yolov2原原本本生硬地部署到树莓派上,结果每一帧检测耗时高达6分钟!!作一帧目标检测花费6分钟这实在是无法忍受的!
如果是用yolov2-tiny的话会快很多,但耗时依旧接近40秒,参考树莓派3B上测试YOLO效果 | CSDN
那树莓派只能跟深度学习无缘了么?那可未必!
Tengine
Tengine 是OPEN AI LAB为嵌入式设备开发的一个轻量级、高性能并且模块化的引擎。
Tengine在嵌入式设备上支持CPU,GPU,DLA/NPU,DSP异构计算的计算框架,实现异构计算的调度器,基于ARM平台的高效的计算库实现,针对特定硬件平台的性能优化,动态规划计算图的内存使用,提供对于网络远端AI计算能力的访问支持,支持多级别并行,整个系统模块可拆卸,基于事件驱动的计算模型,吸取已有AI计算框架的优点,设计全新的计算图表示。
编译安装开源版Tengine
安装相关工具
|
1
|
sudo apt-get instal git cmake |
- git 是一个版本控制系统,稍后将用来从 github 网站上下载Tengine的源码
- cmake 是一个编译工具,用来产生make过程中所需要的Makefile文件
安装支持库
|
1
|
sudo apt-get install libprotobuf-dev protobuf-compiler libboost-all-dev libgoogle-glog-dev libopencv-dev libopenblas-dev |
- protobuf 是一种轻便高效的数据存储格式,这是caffe各种配置文件所使用的数据格式
- boost 是一个c++的扩展程序库,稍后Tengine的编译依赖于该库
- google-glog 是一个google提供的日志系统的程序库
- opencv 是一个开源的计算机视觉库
- openblas 是一个开源的基础线性代数子程序库
下载&编译
- 从github上下载最新的开源版Tengine源码
1
git clone https://github.com/OAID/Tengine.git - 切换工作目录到Tengine
1
cdTengine - 准备好配置文件
Tengine目录下提供了配置模板makefile.config.example文件1cpmakefile.config.example makefile.config - 修改配置文件
makefile.config
由于开源版的Tengine不支持针对armv7的优化,所以需要用openblas替代实现;
将 CONFIG_ARCH_ARM64=y 这一行注释掉(行首加井号 #)以关闭ARM64架构的优化实现;
解除 CONFIG_ARCH_BLAS=y 这一行解除注释(删除行首的井号 #)以开启BLAS计算库的实现方式
- 编译并安装
12
make-j4makeinstall这里的
-j4表示开启四个线程进行编译
测试
- 下载mobilenet-ssd模型并放置在
Tengine/models目录下
下载链接:https://pan.baidu.com/s/1jzPADdCAah4y8NMk3P9Exg - 将工作目录切换到mobilenet-ssd示例程序的目录下1
cd~/Tengine/examples/mobilenet_ssd - 编译示例程序12
cmake –DTENGINE_DIR=/home/pi/Tengine.make这里
-DTENGINE_DIR用于为cmake指定环境变量TENGINE_DIR,该变量可以在CMakeLists.txt文件中找到 - 运行示例程序1
./MSSD可以看到对一张照片进行目标检测,总共耗时1148.32ms
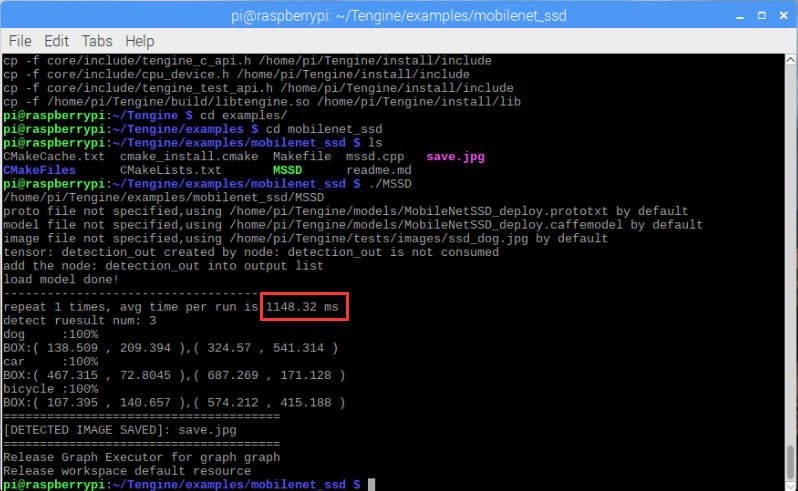
树莓派专用教育版Tengine
最近 Open AI Lab公司 和 浙江大学生物医学工程与仪器科学学院 在嵌入式人工智能领域上开展了教学合作,公司为学院提供了速度更快的针对armv7优化的Tengine版本用于教学用途(已上传到 Github),接下来让我们看看这个树莓派专用教育版的Tengine到底有多快吧!
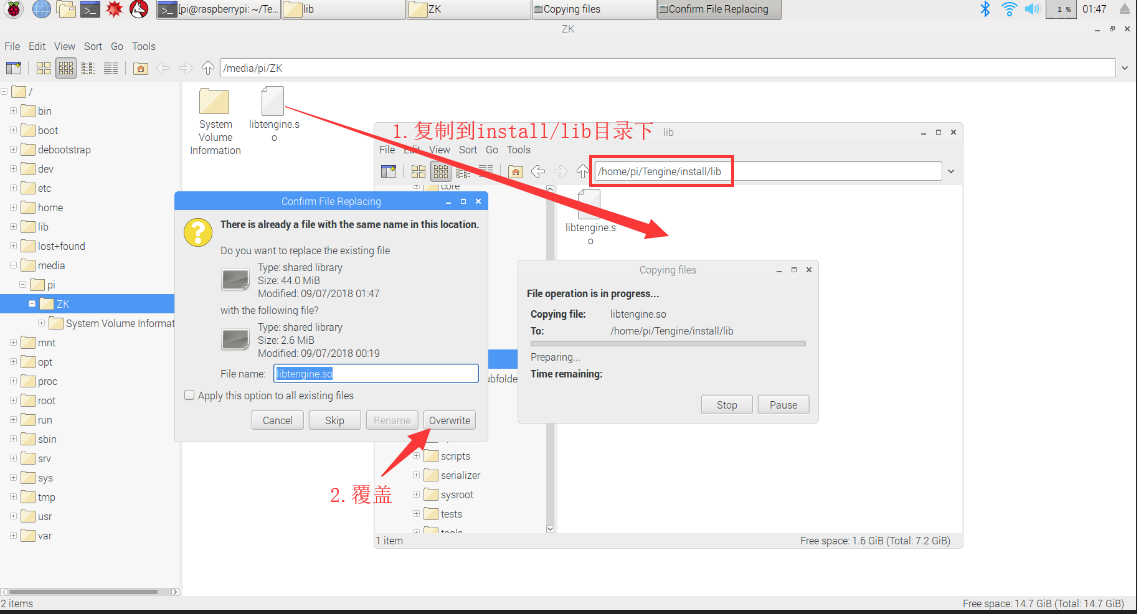
- 用树莓派专用教育版Tengine的动态链接库覆盖掉原先的开源版
动态链接库路径为:Tengine/install/lib/libtengine.so
编译时,make会在build目录下产生libtengine.so动态链接库,而make instll将动态链接库、头文件等拷贝到install目录下
- 重新运行mobilenet-ssd的示例程序
可以看到,单帧耗时从1148.32ms下降为286.136ms,速度有了非常明显的提升!
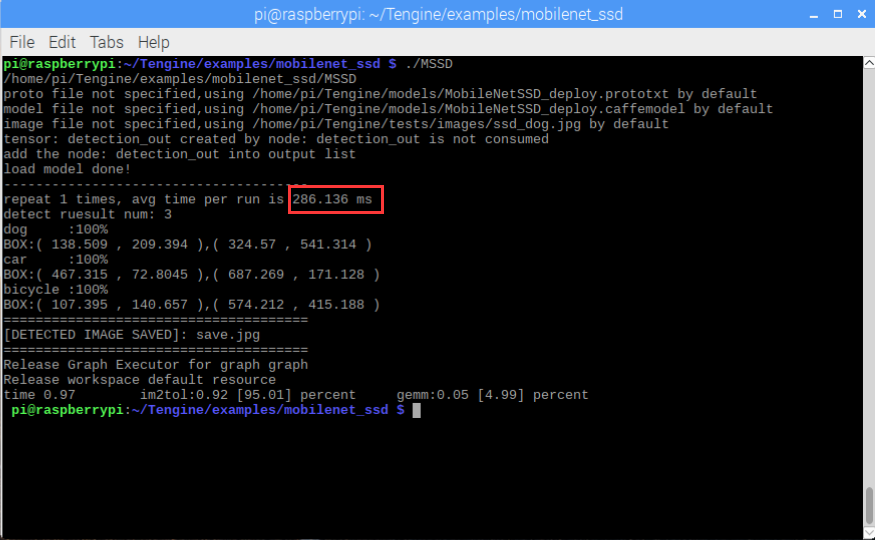
小试牛刀
用上高性能的树莓派专用教育版Tengine,看看mobilenet-ssd在树莓派上能表现如何——
为了方便,视频流直接从mp4文件读取,原始视频如下:
- 从 hey-yahei/my_blog/RasPi-Tengine/mobilenet-ssd | github 上下载源码,并放置在
Tengine/example目录下 - 检查
CMakeLists.txt文件中TENGINE_DIR变量是否正确指向Tengine路径 - 执行
cmake .生成Makefile - 执行
make编译程序 - 执行
./MSSD运行程序
实际效果如下:
由于一部分cpu资源被用于视频的解码工作(对于支持硬解码的平台来说不存在这个问题),可以看到单帧耗时有所下降(400ms-700ms),但对于多数应用场景来说这个帧率是绰绰有余的。
本文开头我们说道,直接在树莓派上配置darknet部署的yolo网络,yolov2单帧耗时接近6分钟,yolov2-tiny单帧耗时接近40秒;而在树莓派上配置Tengine部署的yolov2网络,在blas实现下单帧耗时不到8秒(参考利用Tengine在树莓派上跑深度学习网络 | songrbb),在针对armv7优化实现的教育版下单帧耗时甚至不到2秒!
原文地址:https://shumeipai.nxez.com/2018/12/07/tengine-inference-engine-raspberry-pi-deep-learning.html
本站原创文章,作者:小 编,如若转载,请注明出处:https://www.mzbky.com/1596.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫